Hadoop分布式文件系統(HDFS)是Hadoop生態系統的核心存儲組件,專為大規模數據集上的高吞吐量數據訪問而設計。理解其數據讀取、寫入、存放機制、數據生命周期以及作為數據處理和存儲服務的角色,對于構建高效的大數據平臺至關重要。
一、HDFS核心架構與存放機制
HDFS采用主從(Master/Slave)架構,主要由以下組件構成:
- NameNode(主節點):管理文件系統的命名空間(如目錄樹、文件元數據)以及客戶端對文件的訪問。它不存儲實際數據,而是維護著數據塊(Block)到DataNode的映射關系。
- DataNode(從節點):負責在本地文件系統中存儲實際的數據塊,并響應來自NameNode和客戶端的讀寫請求。
- Secondary NameNode(輔助節點):并非NameNode的熱備,其主要職責是定期合并NameNode的編輯日志(fsimage和edits),以減少NameNode重啟時間,并保存檢查點。
存放機制的核心特點:
- 分塊存儲:文件被分割成一個或多個固定大小的數據塊(默認為128MB或256MB),這些塊是存儲和復制的基本單位。
- 機架感知與副本放置策略:HDFS通過機架感知策略優化可靠性和網絡帶寬。默認的副本因子為3,其經典放置策略是:
- 第一個副本放在客戶端所在的DataNode(若客戶端不在集群內,則隨機選擇)。
- 第二個副本放在不同機架的一個DataNode上。
- 第三個副本放在與第二個副本相同機架的不同DataNode上。
此策略在數據可靠性、讀取帶寬和寫入性能之間取得了平衡。
- 數據均勻分布:NameNode在分配塊存儲時,會盡量考慮各DataNode的存儲負載均衡。
二、數據寫入流程詳解
- 客戶端請求:客戶端通過HDFS客戶端庫調用
create()方法,向NameNode發起創建文件的請求。 - NameNode響應:NameNode檢查權限和命名空間,若無沖突,則在命名空間中創建文件條目,并返回一個
FSDataOutputStream對象給客戶端。 - 管道(Pipeline)建立:客戶端開始寫入數據。數據首先被緩存在本地,積累到一個數據塊大小時,客戶端會從NameNode獲取一個由多個DataNode(如3個)組成的列表,這些DataNode將形成一個寫入管道。客戶端將數據塊依次發送給管道中的第一個DataNode。
- 數據包傳輸與確認:數據被分割成更小的數據包(默認64KB)。第一個DataNode接收數據包,將其存儲到本地,然后轉發給管道中的第二個DataNode,依此類推。每個DataNode存儲數據后,會向上游發送確認包,形成反向的確認管道。
- 塊關閉與最終確認:當一個數據塊的所有數據包都發送完畢并收到所有確認后,該數據塊被視為已寫入。客戶端會通知NameNode文件寫入完成,NameNode將提交文件創建操作(即持久化元數據)。如果管道中的某個DataNode失敗,管道會關閉,剩余的數據塊會被寫入到管道中其他正常的DataNode,并由NameNode在后續安排新的副本復制。
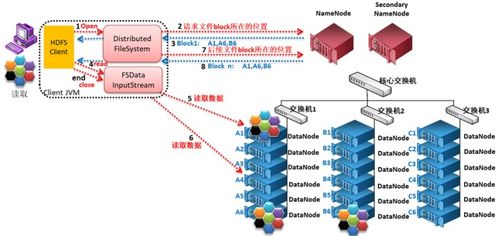
三、數據讀取流程詳解
1. 客戶端請求:客戶端調用open()方法,向NameNode請求獲取文件的數據塊位置信息。
2. NameNode響應:NameNode返回文件前幾個塊(或全部塊,取決于配置和文件大小)的DataNode地址列表,通常按網絡拓撲的臨近性排序(即離客戶端“最近”的優先)。
3. 客戶端直接讀取:客戶端直接聯系離它最近的、擁有該數據塊副本的DataNode,讀取數據。數據以數據包的形式流式傳輸回客戶端。
4. 塊讀取完成與續讀:當一個數據塊讀取完畢,客戶端會關閉與該DataNode的連接,并請求NameNode獲取下一個數據塊的DataNode位置信息,重復此過程,直到文件讀取完成。
這種設計允許高吞吐量的數據訪問,因為讀取流量分散在集群的多個DataNode上,且NameNode只參與元數據交互,不參與實際數據傳輸,避免了瓶頸。
四、數據生命周期與處理
HDFS中的數據生命周期通常包括以下幾個階段:
- 攝入/創建:通過寫入流程將數據存入HDFS。
- 存儲與管理:
- 副本管理:DataNode定期向NameNode發送心跳和塊報告。NameNode根據這些信息檢測副本缺失或損壞(通過校驗和),并觸發復制或刪除操作以維持所需的副本因子。
- 均衡:如果集群中添加了新節點或數據分布不均,Balancer工具可以將數據塊從一個DataNode移動到另一個,以實現存儲均衡。
- 處理與分析:數據作為MapReduce、Spark、Hive等計算框架的輸入源被處理。HDFS的高吞吐特性使其非常適合批處理作業。
- 歸檔與刪除:
- 對于不常訪問的冷數據,可以通過Hadoop歸檔工具(HAR)或與更經濟的存儲層(如通過HDFS聯邦或與對象存儲集成)結合來節省成本。
- 刪除數據時,文件首先被移動到HDFS的“垃圾箱”(trash)目錄(若啟用),在可配置的延遲后才會被永久刪除。在此期間可以恢復。
五、作為數據處理和存儲服務的角色
HDFS不僅僅是一個靜態的存儲系統,更是大數據處理流水線的基石:
- 存儲服務:提供高容錯、高可靠、高擴展性的PB級數據存儲能力,是數據湖架構的核心存儲層。
- 數據處理服務的基礎:其“一次寫入,多次讀取”的模型與批處理范式完美契合。計算任務被調度到存儲數據的DataNode附近(計算向數據遷移),極大減少了網絡傳輸開銷,實現了高效的數據本地化處理。
- 統一命名空間:為上層應用(如Hive、HBase)提供了統一的文件系統視圖,簡化了數據管理。
###
HDFS通過其獨特的分塊、多副本、機架感知的存放機制,以及高效的管道寫入和就近讀取流程,為海量數據提供了可靠的存儲和高速的訪問通道。其數據生命周期管理與強大的容錯能力,確保了數據的持久性和可用性。作為大數據生態的底層存儲基石,HDFS將數據存儲與數據處理緊密耦合,是構建高效、可擴展大數據處理平臺不可或缺的核心服務。